Zooniverse Talk
My messages query: I received the following 2 messages from the project Star Notes on 15/1/2022 but I am not now working on this project. Copied and Pasted the contents for you as under.
I am currently working on two projects, i.e. Architecture Uncovered and Addressing Health - Zooniverse.
1st message refers to Subject 71974208
Again a strange skip on line 9, from 99 to 01. Assuming stictly incrementing numbers, the 01 should be interpreted as MF20701, rather than MF20601. #human_error?
I've seen an identical skip on Subject 71974191, with the exact same plate numbers.
Hops Splurt an hour ago
Subject 71974208
I am sorry you lost your progress!
sydneyevans 20 hours ago
2nd message refers to 7197428
Just started first entry for this page but lost it before finished
Helpful (0) Reply Link Report Edit Delete
RESEARCHER
January 25th 2022, 9:06 pm
I am sorry you lost your progress!
I posted this message a long time ago and then switched to another project.
Perhaps this is why I received another message - but now not working on Star Notes.
Messages received but not doing the projects mentioned.
My messages query: I received the following 2 messages from the project Star Notes on 15/1/2022 but I am not now working on this project. Copied and Pasted the contents for you as under.
I am currently working on two projects, i.e. Architecture Uncovered and Addressing Health - Zooniverse.
1st message refers to Subject 71974208
Again a strange skip on line 9, from 99 to 01. Assuming stictly incrementing numbers, the 01 should be interpreted as MF20701, rather than MF20601. #human_error?
I've seen an identical skip on Subject 71974191, with the exact same plate numbers.
Hops Splurt an hour ago
Subject 71974208
I am sorry you lost your progress!
sydneyevans 20 hours ago
2nd message refers to 7197428
Just started first entry for this page but lost it before finished
Helpful (0) Reply Link Report Edit Delete
RESEARCHER
January 25th 2022, 9:06 pm
I am sorry you lost your progress!
I posted this message a long time ago and then switched to another project.
Perhaps this is why I received another message - but now not working on Star Notes.
2 Participants
5 Comments
I do NOT see a 'Your stats' line at all. I can take some screen snap shots and drop them someplace or e-mail them
Java console has a bunch of error messages.
Failed to load resource: the server responded with a status of 404 (Not Found)
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
https://panoptes.zooniverse.org/api/users/90/avatar Failed to load resource: the server responded with a status of 404 (Not Found)
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
https://panoptes.zooniverse.org/api/users/90/profile_header Failed to load resource: the server responded with a status of 404 (Not Found)
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No profile_header exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
vendor.c12b7a87db2fa649b51b71189851ea12.js:12 GET https://panoptes.zooniverse.org/api/users/90/avatar 404 (Not Found)(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12o @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.request @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.get @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12undefined.t.exports.o.createClass.handleResourceChange @ main.106c2852dba2f8bffd380dbf38ade8c4.js:12undefined.t.exports.o.createClass.componentDidMount @ main.106c2852dba2f8bffd380dbf38ade8c4.js:12i.notifyAll @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7f.close @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10o.closeAll @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11m.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11E @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.closeAll @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11d.batchedUpdates @ vendor.c12b7a87db2fa649b51b71189851ea12.js:9u @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11r @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10d.enqueueElementInternal @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10H.scrollMonitor @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10H._updateRootComponent @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10H.render @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10(anonymous function) @ main.106c2852dba2f8bffd380dbf38ade8c4.js:6L @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6r.to @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6r.from @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6l.createClass.statics.dispatch @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7l.createClass.statics.handleLocationChange @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7r @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7i @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
vendor.c12b7a87db2fa649b51b71189851ea12.js:12 GET https://panoptes.zooniverse.org/api/users/90/avatar 404 (Not Found)(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12o @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.request @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.get @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12undefined.t.exports.o.createClass.handleResourceChange @ main.106c2852dba2f8bffd380dbf38ade8c4.js:12a @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.exports.e.emit @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.exports.t.create @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.processResponse @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
Will the old ribbons and stats be transfered to the new layout?
I do NOT see a 'Your stats' line at all. I can take some screen snap shots and drop them someplace or e-mail them
Java console has a bunch of error messages.
Failed to load resource: the server responded with a status of 404 (Not Found)
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
https://panoptes.zooniverse.org/api/users/90/avatar Failed to load resource: the server responded with a status of 404 (Not Found)
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
https://panoptes.zooniverse.org/api/users/90/profile_header Failed to load resource: the server responded with a status of 404 (Not Found)
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No profile_header exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
vendor.c12b7a87db2fa649b51b71189851ea12.js:12 GET https://panoptes.zooniverse.org/api/users/90/avatar 404 (Not Found)(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12o @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.request @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.get @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12undefined.t.exports.o.createClass.handleResourceChange @ main.106c2852dba2f8bffd380dbf38ade8c4.js:12undefined.t.exports.o.createClass.componentDidMount @ main.106c2852dba2f8bffd380dbf38ade8c4.js:12i.notifyAll @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7f.close @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10o.closeAll @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11m.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11E @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.closeAll @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11o.perform @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11d.batchedUpdates @ vendor.c12b7a87db2fa649b51b71189851ea12.js:9u @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11r @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10d.enqueueElementInternal @ vendor.c12b7a87db2fa649b51b71189851ea12.js:11(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10H.scrollMonitor @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10H._updateRootComponent @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10H.render @ vendor.c12b7a87db2fa649b51b71189851ea12.js:10(anonymous function) @ main.106c2852dba2f8bffd380dbf38ade8c4.js:6L @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6r.to @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6r.from @ vendor.c12b7a87db2fa649b51b71189851ea12.js:6l.createClass.statics.dispatch @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7l.createClass.statics.handleLocationChange @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7r @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7i @ vendor.c12b7a87db2fa649b51b71189851ea12.js:7
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
vendor.c12b7a87db2fa649b51b71189851ea12.js:12 GET https://panoptes.zooniverse.org/api/users/90/avatar 404 (Not Found)(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12o @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.request @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.(anonymous function) @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.get @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12undefined.t.exports.o.createClass.handleResourceChange @ main.106c2852dba2f8bffd380dbf38ade8c4.js:12a @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.exports.e.emit @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.exports.t.create @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12t.processResponse @ vendor.c12b7a87db2fa649b51b71189851ea12.js:12
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)a.handleError @ main.106c2852dba2f8bffd380dbf38ade8c4.js:1
main.106c2852dba2f8bffd380dbf38ade8c4.js:1 Uncaught (in promise) Error: No avatar exists for user #90
at t.a.handleError (https://www.zooniverse.org/main.106c2852dba2f8bffd380dbf38ade8c4.js:1:9498)
20 Participants
73 Comments
I have been trying to beat these errors by improving the python script to reduce the calls to the API, reduce the time the subject set object must remain open and add subjects to the subject set using a lists of subjects 100 at a time rather than one at a time. As well I added some retries into the step to add the subjects to the subject set, reloading the subject set object if the previous attempt to add the list of 100 subjects failed, with up to three retries.
The modified script is here. Basically the script is to import metadata from a manifest and create 5531 two frame image subjects from tinder URL's, and add them to a subject set. (YES I know this is nothing that the CLI can not do and likely better, but I am trying to figure out how to salvage dozens of custom uploaders written over the past 8 years for several teams that do things the cli can not such as extract exif metadata and compress media)
Trials:
These first trials were with this environment:
Python version: 3.10.2
panoptes-client: 1.6.1
requests: 2.28.2
urllib3: 1.26.14
SSL version: OpenSSL 1.1.1m 14 Dec 2021
The first run failed after creating 2969 subjects with the error being a loss of connection terminated by zooniverse :
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
The second run completed creating the 5531 subjects and successfully added them to the subject set with no errors YEAH!
The third run completed creating the 5531 subjects but failed during the add-to-subject set step after adding about 1100 subjects. Again the error being a loss of connection terminated by zooniverse :
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
I restarted just the add to the subject set step and the second time that completed with no errors.
So far no SSL or stale object errors, but 2 of 3 tries failed for loss of connection.....
The next group of trials was with this environment:
Python version: 3.12.4
panoptes-client: 1.6.2
requests: 2.32.3
urllib3: 2.2.2
SSL version: OpenSSL 3.0.13 30 Jan 2024
The first run with this environment completed creating the 5531 subjects and successfully added them to the subject set with no errors YEAH!
The second run with this environment completed creating the 5531 subjects and successfully added them to the subject set with no errors YEAH!
A third run failed 3344 subjects into the create subject step with again the error being a loss of connection terminated by zooniverse :
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) I proceeded to add those subjects to the set (with no errors) then manually modified the manifest and restarted the script where it left off. The remaining 2178 subjects were created without errors and were successfully added to the subject set with no errors.
Again no SSL or stale object errors, just connectivity errors... I am going to turn on the debugging and try again to see if we can catch what's dropping the connection.
Common errors when uploading through CLI
I have been trying to beat these errors by improving the python script to reduce the calls to the API, reduce the time the subject set object must remain open and add subjects to the subject set using a lists of subjects 100 at a time rather than one at a time. As well I added some retries into the step to add the subjects to the subject set, reloading the subject set object if the previous attempt to add the list of 100 subjects failed, with up to three retries.
The modified script is here. Basically the script is to import metadata from a manifest and create 5531 two frame image subjects from tinder URL's, and add them to a subject set. (YES I know this is nothing that the CLI can not do and likely better, but I am trying to figure out how to salvage dozens of custom uploaders written over the past 8 years for several teams that do things the cli can not such as extract exif metadata and compress media)
Trials:
These first trials were with this environment:
Python version: 3.10.2
panoptes-client: 1.6.1
requests: 2.28.2
urllib3: 1.26.14
SSL version: OpenSSL 1.1.1m 14 Dec 2021
The first run failed after creating 2969 subjects with the error being a loss of connection terminated by zooniverse :
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
The second run completed creating the 5531 subjects and successfully added them to the subject set with no errors YEAH!
The third run completed creating the 5531 subjects but failed during the add-to-subject set step after adding about 1100 subjects. Again the error being a loss of connection terminated by zooniverse :
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
I restarted just the add to the subject set step and the second time that completed with no errors.
So far no SSL or stale object errors, but 2 of 3 tries failed for loss of connection.....
The next group of trials was with this environment:
Python version: 3.12.4
panoptes-client: 1.6.2
requests: 2.32.3
urllib3: 2.2.2
SSL version: OpenSSL 3.0.13 30 Jan 2024
The first run with this environment completed creating the 5531 subjects and successfully added them to the subject set with no errors YEAH!
The second run with this environment completed creating the 5531 subjects and successfully added them to the subject set with no errors YEAH!
A third run failed 3344 subjects into the create subject step with again the error being a loss of connection terminated by zooniverse :
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) I proceeded to add those subjects to the set (with no errors) then manually modified the manifest and restarted the script where it left off. The remaining 2178 subjects were created without errors and were successfully added to the subject set with no errors.
Again no SSL or stale object errors, just connectivity errors... I am going to turn on the debugging and try again to see if we can catch what's dropping the connection.
5 Participants
58 Comments
The length of the traceback is not surprising - there are a number of chained modules called in just about any command line. This most recent example is pretty much what I would expect for a misspelt manifest name.
On a stable internet connection I would expect the CLI to work with thousands of subjects, though I have to admit I have never used it beyond testing.
I have had issues with the Python panoptes client where I was linking many thousand images to a subject set - they all linked successfully but there were unexplained errors. It appeared that the panoptes API would do the linkage but some sort of communication error was raised. At first I tried to catch and handle the errors - which got the subjects linked and the job done. On the last run I removed the error handling trying to force the issue and find out exactly what was happening but on that run 5000 subjects linked and reported no errors so there is still a bit of a mystery! 
For your first two examples the error appears to be related to communications. It is possible that your internet connection with zooniverse is not handling the to and fro flow of information correctly and there is a sync problem - unlike downloading a web page, uploading has much more two way information flow - small delays in the routing and transmission rates may have responses arriving when the system is expecting something else. At the zooniverse end the API is handling many tasks near simultaneously, not just you job, so there may be specific situations where things break down.
I would expect the last line of the error traceback would hold some clue if the problem is at your end - as in this latest example clearly the misspelt manifest sends the system looking for files that do not exist.
I would advise switching to the Python Client rather than the CLI. That way you can write error handling into a small script. This will keep the process alive and you can continue uploading. Then you can query the subject set and determine what did and what did not upload and retry those that need it.
This [link](+tab+ https://github.com/PmasonFF/Zooniverse-data-digging/tree/master/Panoptes_client_examples) is an untested Python 2 script that is my best shot at modifying a working Python 3 script for uploading subjects using the python panoptes client. It accepts an directory location and a subject set name. It finds all image files in the directory and adds their Filename as the only metadata. If you want additional metadata uploaded you can modify the code to retrieve it and add it to the metadata dictionaries as they are built or you can leave it and update the metadata later after the subjects are created and uploaded (Either approach needs an additional python script).
It finds or creates the subject set and uploads the files and metadata. It then produces a file of the subjects successfully created. Hopefully there are only a few things I might have missed and you can debug this easily. If you do use it please let me know what issues it has, either here or in Github and I will correct the code for others.
Peter
Problem with command line uploader
The length of the traceback is not surprising - there are a number of chained modules called in just about any command line. This most recent example is pretty much what I would expect for a misspelt manifest name.
On a stable internet connection I would expect the CLI to work with thousands of subjects, though I have to admit I have never used it beyond testing.
I have had issues with the Python panoptes client where I was linking many thousand images to a subject set - they all linked successfully but there were unexplained errors. It appeared that the panoptes API would do the linkage but some sort of communication error was raised. At first I tried to catch and handle the errors - which got the subjects linked and the job done. On the last run I removed the error handling trying to force the issue and find out exactly what was happening but on that run 5000 subjects linked and reported no errors so there is still a bit of a mystery!
For your first two examples the error appears to be related to communications. It is possible that your internet connection with zooniverse is not handling the to and fro flow of information correctly and there is a sync problem - unlike downloading a web page, uploading has much more two way information flow - small delays in the routing and transmission rates may have responses arriving when the system is expecting something else. At the zooniverse end the API is handling many tasks near simultaneously, not just you job, so there may be specific situations where things break down.
I would expect the last line of the error traceback would hold some clue if the problem is at your end - as in this latest example clearly the misspelt manifest sends the system looking for files that do not exist.
I would advise switching to the Python Client rather than the CLI. That way you can write error handling into a small script. This will keep the process alive and you can continue uploading. Then you can query the subject set and determine what did and what did not upload and retry those that need it.
This [link](+tab+ https://github.com/PmasonFF/Zooniverse-data-digging/tree/master/Panoptes_client_examples) is an untested Python 2 script that is my best shot at modifying a working Python 3 script for uploading subjects using the python panoptes client. It accepts an directory location and a subject set name. It finds all image files in the directory and adds their Filename as the only metadata. If you want additional metadata uploaded you can modify the code to retrieve it and add it to the metadata dictionaries as they are built or you can leave it and update the metadata later after the subjects are created and uploaded (Either approach needs an additional python script).
It finds or creates the subject set and uploads the files and metadata. It then produces a file of the subjects successfully created. Hopefully there are only a few things I might have missed and you can debug this easily. If you do use it please let me know what issues it has, either here or in Github and I will correct the code for others.
Peter
3 Participants
7 Comments
Well, it did something. Now:
If I open the Cedar Creek project and click classify while I'm signed in, instead of getting a blank white screen I get the same error message as I got earlier (I copied it below), with the black zooniverse menu bar at the top of the screen. At that point, if I click on my username and sign out, the Cedar Creek Classify page does come up and I can use it normally. (Before, the menu bar wasn't there and I had to close the program and start over.)
If I open the program while I'm not signed in and click classify, and then while the classify page is active I go ahead and sign in, the classify page does come up and I can use it but the error message is printed at the bottom or it. Before the classify page didn't come up at all unless I was on the 'talk' page (which doesn't have the picture you can enlarge etc, for what that's worth). The error message stays at the bottom of the page but doesn't seem to cause any problems, I can classify as usual. This is the error message (same as before):
There was an error retrieving project meredithspalmer/cedar-creek-eyes-on-the-wild.
Minified React error #185; visit https://reactjs.org/docs/error-decoder.html?invariant=185 for the full message or use the non-minified dev environment for full errors and additional helpful warnings.
in SizeMe(M)
in t
in t
in div
in t
in l
in Connect(l)
in div
in t
in Connect(t)
in div
in div
in div
in Unknown
in div
in PanoptesApp
in RouterContext
in t
in Router
in o
Can't classify if I'm signed in in Cedar Creek Eyes ont the Wild
Well, it did something. Now:
If I open the Cedar Creek project and click classify while I'm signed in, instead of getting a blank white screen I get the same error message as I got earlier (I copied it below), with the black zooniverse menu bar at the top of the screen. At that point, if I click on my username and sign out, the Cedar Creek Classify page does come up and I can use it normally. (Before, the menu bar wasn't there and I had to close the program and start over.)
If I open the program while I'm not signed in and click classify, and then while the classify page is active I go ahead and sign in, the classify page does come up and I can use it but the error message is printed at the bottom or it. Before the classify page didn't come up at all unless I was on the 'talk' page (which doesn't have the picture you can enlarge etc, for what that's worth). The error message stays at the bottom of the page but doesn't seem to cause any problems, I can classify as usual. This is the error message (same as before):
There was an error retrieving project meredithspalmer/cedar-creek-eyes-on-the-wild.
Minified React error #185; visit https://reactjs.org/docs/error-decoder.html?invariant=185 for the full message or use the non-minified dev environment for full errors and additional helpful warnings.
in SizeMe(M)
in t
in t
in div
in t
in l
in Connect(l)
in div
in t
in Connect(t)
in div
in div
in div
in Unknown
in div
in PanoptesApp
in RouterContext
in t
in Router
in o
4 Participants
21 Comments
When I run the command "pip install panoptes-client", an error occurs.
The error says "failed with error code 1 in /tmp/pip-build-051g7kst/future" and that it has instead installed version 7.1.2 instead of 10.0.1. I've copied the full error below.
I know I've installed a version of panoptes, but when I try to run the line "from panoptes_client import Panoptes, Project" it gives me an error. It says "ImportError: No module named panoptes_client". I have a feeling this is related to my failure to install 10.0.1, but I'm not certain. I'm essentially trying to follow the instructions here, but it's not working the way I'm expecting it to. Can you help?
Full error message:
Command "/usr/bin/python3 -c "import setuptools, tokenize;file='/tmp/pip-build-051g7kst/future/setup.py';exec(compile(getattr(tokenize, 'open', open)(file).read().replace('\r\n', '\n'), file, 'exec'))" install --record /tmp/pip-2fj56m1u-record/install-record.txt --single-version-externally-managed --compile " failed with error code 1 in /tmp/pip-build-051g7kst/future
You are using pip version 7.1.2, however version 10.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
Problems Importing Panoptes Client
When I run the command "pip install panoptes-client", an error occurs.
The error says "failed with error code 1 in /tmp/pip-build-051g7kst/future" and that it has instead installed version 7.1.2 instead of 10.0.1. I've copied the full error below.
I know I've installed a version of panoptes, but when I try to run the line "from panoptes_client import Panoptes, Project" it gives me an error. It says "ImportError: No module named panoptes_client". I have a feeling this is related to my failure to install 10.0.1, but I'm not certain. I'm essentially trying to follow the instructions here, but it's not working the way I'm expecting it to. Can you help?
Full error message:
Command "/usr/bin/python3 -c "import setuptools, tokenize;file='/tmp/pip-build-051g7kst/future/setup.py';exec(compile(getattr(tokenize, 'open', open)(file).read().replace('\r\n', '\n'), file, 'exec'))" install --record /tmp/pip-2fj56m1u-record/install-record.txt --single-version-externally-managed --compile " failed with error code 1 in /tmp/pip-build-051g7kst/future
You are using pip version 7.1.2, however version 10.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
5 Participants
6 Comments
Hi all (attn: @Pmason @arw36 ) --
I was able to run upload trials using Python environments that match the ones you report.
@arw36 -- I was not able to reproduce any of the SSL errors you were reporting. I'm not sure what next step would be best from here, other than trying a fresh install of a Python environment -- perhaps one that uses Anaconda or miniconda as a package manager (based on possibility that using a mix of user-installed and OS-managed packages can cause issues, but I have no specific evidence that this is the source of your specific issues). I've emailed you and @Pmason to find a time to set up a call to discuss.
@Pmason -- I was able to reproduce the occasional 409 error resulting from a stale SubjectSet. This is discouraging because we have previously taken action to prevent these errors (see this PR), but discussions with Zoo devs have led to at least one potential code change we can make and test. I'm currently performing some additional logging and testing of Etags (the resource property that leads to a resource being declared stale), as well as following up on the potential Panoptes API code change.
For now, the best possible workaround for these intermittent Client upload issues would be to pre-process all subject data (create and compress images, collate and compile metadata, etc) such that you can run a single upload with an accompanying manifest file via the CLI. The CLI offers the best error catching and restart capability in the case of 409 or SSL errors. I acknowledge that if the error rate is sufficiently high, uploads become untenable even with CLI restarts. However, with the current observed rate of 409 errors, I believe the CLI is still a workable solution at present, but the Zoo team continues to work actively to alleviate remaining issues.
Common errors when uploading through CLI
Hi all (attn: @Pmason @arw36 ) --
I was able to run upload trials using Python environments that match the ones you report.
@arw36 -- I was not able to reproduce any of the SSL errors you were reporting. I'm not sure what next step would be best from here, other than trying a fresh install of a Python environment -- perhaps one that uses Anaconda or miniconda as a package manager (based on possibility that using a mix of user-installed and OS-managed packages can cause issues, but I have no specific evidence that this is the source of your specific issues). I've emailed you and @Pmason to find a time to set up a call to discuss.
@Pmason -- I was able to reproduce the occasional 409 error resulting from a stale SubjectSet. This is discouraging because we have previously taken action to prevent these errors (see this PR), but discussions with Zoo devs have led to at least one potential code change we can make and test. I'm currently performing some additional logging and testing of Etags (the resource property that leads to a resource being declared stale), as well as following up on the potential Panoptes API code change.
For now, the best possible workaround for these intermittent Client upload issues would be to pre-process all subject data (create and compress images, collate and compile metadata, etc) such that you can run a single upload with an accompanying manifest file via the CLI. The CLI offers the best error catching and restart capability in the case of 409 or SSL errors. I acknowledge that if the error rate is sufficiently high, uploads become untenable even with CLI restarts. However, with the current observed rate of 409 errors, I believe the CLI is still a workable solution at present, but the Zoo team continues to work actively to alleviate remaining issues.
5 Participants
58 Comments
I received following e-mail by the Zooniverse Server.:
Wed, 23 Mar 2016 00:17:40
You have been automatically removed from the ZOONIVERSE list (Zooniverse Participants Announcement List) as a result of repeated delivery error reports from your mail system. This decision was based on the list's automatic error monitoring policy and has not been reviewed or otherwise confirmed by a person. If you receive this message, then it means that something is wrong. While you are obviously able to receive mail, your mail system has been regularly reporting that your account did not exist, or that you were otherwise permanently unable to receive mail. Here is some information that may assist you or your local help desk in determining the cause of the problem:
- The failing address is (...) .
- The first error was reported on 2016-03-22.
- Since then, a total of 1 delivery errors have been received.
(...)
Please do not ignore this message. While you can re-subscribe to the list, it is important for you to report this problem to your mail administrator so that it can be solved. This problem is not specific to the ZOONIVERSE list and may also affect your private mail. This means that you may have lost some private mail as well. Anyone trying to write to you during the same time frame might have received the same errors for the same reason.
BTW, another volunteer had reported such an e-mail in GZ Talk three years ago.:
"Your Removal from the GALAXYZOO list?"
https://talk.galaxyzoo.org/#/boards/BGZ0000003/discussions/DGZ1006d8s
In the e-mail there is said, that I "can re-subscribe to the list"! So I checked my "Zooniverse e-mail settings".:
Curiously, the three "click boxes" (Zooniverse email preferences) aren't empty, though it is stated in the e-mail, that my e-mail address was automatically removed from the Zooniverse list!
I didn't receive an e-mail (Zooniverse Newsletter) on 22.03. (server message: "first error was reported on 2016-03-22")!
Will I receive Zooniverse Newsletters by e-mail again in the future?
Automatic removal from the ZOONIVERSE list
I received following e-mail by the Zooniverse Server.:
Wed, 23 Mar 2016 00:17:40
You have been automatically removed from the ZOONIVERSE list (Zooniverse Participants Announcement List) as a result of repeated delivery error reports from your mail system. This decision was based on the list's automatic error monitoring policy and has not been reviewed or otherwise confirmed by a person. If you receive this message, then it means that something is wrong. While you are obviously able to receive mail, your mail system has been regularly reporting that your account did not exist, or that you were otherwise permanently unable to receive mail. Here is some information that may assist you or your local help desk in determining the cause of the problem:
- The failing address is (...) .
- The first error was reported on 2016-03-22.
- Since then, a total of 1 delivery errors have been received.
(...)
Please do not ignore this message. While you can re-subscribe to the list, it is important for you to report this problem to your mail administrator so that it can be solved. This problem is not specific to the ZOONIVERSE list and may also affect your private mail. This means that you may have lost some private mail as well. Anyone trying to write to you during the same time frame might have received the same errors for the same reason.
BTW, another volunteer had reported such an e-mail in GZ Talk three years ago.:
"Your Removal from the GALAXYZOO list?"
https://talk.galaxyzoo.org/#/boards/BGZ0000003/discussions/DGZ1006d8s
In the e-mail there is said, that I "can re-subscribe to the list"! So I checked my "Zooniverse e-mail settings".:
Curiously, the three "click boxes" (Zooniverse email preferences) aren't empty, though it is stated in the e-mail, that my e-mail address was automatically removed from the Zooniverse list!
I didn't receive an e-mail (Zooniverse Newsletter) on 22.03. (server message: "first error was reported on 2016-03-22")!
Will I receive Zooniverse Newsletters by e-mail again in the future?
5 Participants
11 Comments
I have had a look at some of the scans on the ISTAT website. These are in very high resolution and I would expect very high accuracy from OCR - particularly if the OCR software is trained on the specific font used, and for table data limited to certain characters.
Possibly use zooniverse to mark the pages so that you could automate the process of preparing sections of the high res image for injection into the OCR process ie use zooniverse people to mark a specific column of figures. Use the marks to crop out the column from the highest resolution source image, apply OCR to the cropped image to convert it to text, possibly use zooniverse again to proof and mark/correct errors, then convert the corrected text back into a digital record by inserting the appropriate bits in the record fomat you ultimately require.
This crop from one table is a screen shot - not even a crop from an actual high res image!

And this is the OCR output using tesseract with no training on this specific font, nor any limits on the characters to be recognized:
24.457
6.193
(b) 9.060
8.860
4.222
3.257
12.358
1.628
19.203
7.978
Using OCR requires careful image preparation and high resolution. You have the resolution required - you just need to automate the process of cropping out sections of the image to feed to OCR software. zooniverse and some python scripts could help you do that! I have scripts that accept a rectangle drawn on an image by zooites, scales that appropriately to use it to crop out that area of the corresponding high resolution image and save it. The saved crops would be fed to an OCR engine to get text columns corresponding to the rectangle region of the original scan
Once you have the content as text you could possibly use zooniverse to compare the original images and the text version to mark errors and suggest corrections. You would have to add the text to a image with the cropped region side by side (again using an automated image manipulation) and present those as images with a workflow to draw rectangles around errors and transcribe a correction as a subtask to the drawing:

In this way you could break the process of digitizing approximately 700 fields per page (X92X10+ pages?? )into:
Your original workflow to identify the tables and other page types,
A workflow to mark each column and identify which column it is for each table,
An automated analysis step to produce the crops of each column, feed that to an OCR engine, and return text corresponding to the column,
An automated process to add the text column, suitably scaled, to an image at a suitable resolution of the crop of that region, and upload these to zooniverse
A workflow to present these for proof and error correction
An automated process to apply error correction to the text columns based on the zooniverse data and finally extract the entity-variable-value triplets based on the text column entries and spatial correspondence between columns on the original page.
If you believe you can not use OCR, then you have to somehow break the transcription process up into small bits that can be completed in one classification, since the standard project builder has no means of sharing the classification of a subject over many volunteers. Yes - there are projects that have this ability (Annotate) but they have a customized front end. Weather Rescue used the standard project builder for transcription of tabular data (though the tables were smaller) Note they broke the task down into very small steps, asking only for a few entries per classification.
If you use straight up transcription you will need to have a means of reconciling various versions as entered by the volunteers. This is not a trivial task and proofing and error correction is a big job!
Census: Digitise census table
I have had a look at some of the scans on the ISTAT website. These are in very high resolution and I would expect very high accuracy from OCR - particularly if the OCR software is trained on the specific font used, and for table data limited to certain characters.
Possibly use zooniverse to mark the pages so that you could automate the process of preparing sections of the high res image for injection into the OCR process ie use zooniverse people to mark a specific column of figures. Use the marks to crop out the column from the highest resolution source image, apply OCR to the cropped image to convert it to text, possibly use zooniverse again to proof and mark/correct errors, then convert the corrected text back into a digital record by inserting the appropriate bits in the record fomat you ultimately require.
This crop from one table is a screen shot - not even a crop from an actual high res image!
And this is the OCR output using tesseract with no training on this specific font, nor any limits on the characters to be recognized:
24.457
6.193
(b) 9.060
8.860
4.222
3.257
12.358
1.628
19.203
7.978
Using OCR requires careful image preparation and high resolution. You have the resolution required - you just need to automate the process of cropping out sections of the image to feed to OCR software. zooniverse and some python scripts could help you do that! I have scripts that accept a rectangle drawn on an image by zooites, scales that appropriately to use it to crop out that area of the corresponding high resolution image and save it. The saved crops would be fed to an OCR engine to get text columns corresponding to the rectangle region of the original scan
Once you have the content as text you could possibly use zooniverse to compare the original images and the text version to mark errors and suggest corrections. You would have to add the text to a image with the cropped region side by side (again using an automated image manipulation) and present those as images with a workflow to draw rectangles around errors and transcribe a correction as a subtask to the drawing:
In this way you could break the process of digitizing approximately 700 fields per page (X92X10+ pages?? )into:
Your original workflow to identify the tables and other page types,
A workflow to mark each column and identify which column it is for each table,
An automated analysis step to produce the crops of each column, feed that to an OCR engine, and return text corresponding to the column,
An automated process to add the text column, suitably scaled, to an image at a suitable resolution of the crop of that region, and upload these to zooniverse
A workflow to present these for proof and error correction
An automated process to apply error correction to the text columns based on the zooniverse data and finally extract the entity-variable-value triplets based on the text column entries and spatial correspondence between columns on the original page.
If you believe you can not use OCR, then you have to somehow break the transcription process up into small bits that can be completed in one classification, since the standard project builder has no means of sharing the classification of a subject over many volunteers. Yes - there are projects that have this ability (Annotate) but they have a customized front end. Weather Rescue used the standard project builder for transcription of tabular data (though the tables were smaller) Note they broke the task down into very small steps, asking only for a few entries per classification.
If you use straight up transcription you will need to have a means of reconciling various versions as entered by the volunteers. This is not a trivial task and proofing and error correction is a big job!
3 Participants
5 Comments
Sorry for the time delay - I was Xmas shopping - early for me this year - it is only the 21st!
From your note that you are working with my script already, I am going to assume you can at this point
open the editor
create new project and a new file
make a small python script and save it
find and open that script with the editor and run it.
use your OS to move the file to a new location and
use the editor to find load and run the script from a new location.
Further I understand you have copied
flatten_class_frame.py from the Git to a directory
and can load it into the editor
and have modified the file locations.
At this point If you are using Pycharm any errors in the code as determined by the editor code checking function would show as red underlines and or red dashes on the right of the editor this screen shot is an example missing a quote mark on the input file location in line 23:
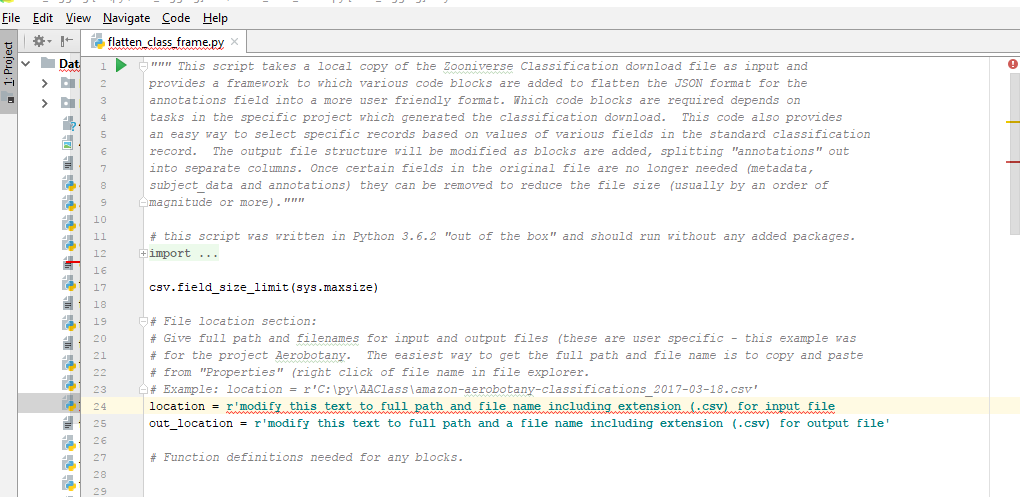
If the editor error checking is good there will be a green check in the upper right ( or as least a amber square that will say there are typos and minor errors this script throws a "unused import" warning ( which is not problem to running it) with my editor setting but yours may differ.
If that is the case then attempt to run the script and tell me what errors you have get at the bottom of the screen where the editor reports the program progress and exit status.
If there are no errors and the script exits with exit code 0 look to see if there is a copy of the classification file or at least part of it (the git version is set to cut off the first 150000 records as a default) under the name and location you gave it in the out_location in line 24.
If you can get this far then start playing with the criteria in the function "def include(class_record)" so you can slice out parts of the classification file any way you might like. Change one thing at a time and see what it does. You will likely cause some errors - try to figure out what might be the issue but use Cntr-Z to undo back to a working version. In the worse case you can always go back to the git at square one, or copy any working version to a new .py file using the OS and reload that.
If you are working with a big classification download file in the "location" line 23 then set the line 99 "if i == 150000:" to something smaller like 10000 so you do not have to wait for the processing of all the records each trial.
Once you have the ability to select a specific workflow or range of subject_ids, or any of the other options you might need we would be ready to tackle something more such as flattening the Json strings in the annotations column by adding a building block to the basic frame you are working with now.
If you are whizzing through this and I am being to pedantic let me know and we can jump right into the survey task - it is very difficult to judge how someone is doing via these messages....
Issues with python
Sorry for the time delay - I was Xmas shopping - early for me this year - it is only the 21st!
From your note that you are working with my script already, I am going to assume you can at this point
open the editor
create new project and a new file
make a small python script and save it
find and open that script with the editor and run it.
use your OS to move the file to a new location and
use the editor to find load and run the script from a new location.
Further I understand you have copied
flatten_class_frame.py from the Git to a directory
and can load it into the editor
and have modified the file locations.
At this point If you are using Pycharm any errors in the code as determined by the editor code checking function would show as red underlines and or red dashes on the right of the editor this screen shot is an example missing a quote mark on the input file location in line 23:
If the editor error checking is good there will be a green check in the upper right ( or as least a amber square that will say there are typos and minor errors this script throws a "unused import" warning ( which is not problem to running it) with my editor setting but yours may differ.
If that is the case then attempt to run the script and tell me what errors you have get at the bottom of the screen where the editor reports the program progress and exit status.
If there are no errors and the script exits with exit code 0 look to see if there is a copy of the classification file or at least part of it (the git version is set to cut off the first 150000 records as a default) under the name and location you gave it in the out_location in line 24.
If you can get this far then start playing with the criteria in the function "def include(class_record)" so you can slice out parts of the classification file any way you might like. Change one thing at a time and see what it does. You will likely cause some errors - try to figure out what might be the issue but use Cntr-Z to undo back to a working version. In the worse case you can always go back to the git at square one, or copy any working version to a new .py file using the OS and reload that.
If you are working with a big classification download file in the "location" line 23 then set the line 99 "if i == 150000:" to something smaller like 10000 so you do not have to wait for the processing of all the records each trial.
Once you have the ability to select a specific workflow or range of subject_ids, or any of the other options you might need we would be ready to tackle something more such as flattening the Json strings in the annotations column by adding a building block to the basic frame you are working with now.
If you are whizzing through this and I am being to pedantic let me know and we can jump right into the survey task - it is very difficult to judge how someone is doing via these messages....
3 Participants
29 Comments