
Finished! Looks like this project is out of data at the moment!
Thank you to all the volunteers who have participated in Scarlets and Blues. The project data is now available for reuse. For details, see the Results page (https://tanc-ahrc.github.io/EngagingCrowds/Data.html). All data is presented in an anonymised form. If you used a Zooniverse account to participate in this project and would like to request for your anonymised data to be deleted, please contact research@nationalarchives.gov.uk.
© Images used in Scarlets and Blues are reproduced by permission of The National Archives, UK.
The National Archives does not guarantee the accuracy, completeness or fitness for the purpose of the information provided. Images may be used only for purposes of research, private study or education. Applications for any other use should be made to The National Archives Image Library.
FAQ
What licensing terms apply to the images used in the project?
© Images used in Scarlets and Blues are reproduced by permission of The National Archives, UK.
The National Archives does not guarantee the accuracy, completeness or fitness for the purpose of the information provided. Images may be used only for purposes of research, private study or education. Applications for any other use should be made to The National Archives Image Library.
Please visit The National Archives catalogue, Discovery, to view images used in Scarlets and Blues.
What will happen to the transcriptions that I create? On what terms will they be made available?
The aim of Scarlets and Blues is to create data that will become freely available for research. Some of this data will become part of The National Archives’ online catalogue, Discovery and be used in future research projects. We are grateful to all those who contribute their time and expertise to help us achieve this aim.
The National Archives is a government department, which means that all of the material we create is subject to Crown copyright.
The National Archives will make data produced by volunteers available for use and re-use under the terms of the Open Government Licence (OGL). This licence allows people to copy, publish and distribute information, as long as they acknowledge its source. It is compatible with the Creative Commons Attribution License 4.0 and the Open Data Commons Attribution License.
By contributing to this project, you agree to assign the rights to any material you create to the Crown so that it can be freely re-used under OGL terms. This includes assignment of any rights granted by copyright, such as moral rights, database rights or other intellectual property rights that will or may subsist in material created in the course of this project.
What are the records?
The records are the pages of minute books of the meetings of the Special Board of the Royal Hospital Chelsea, covering the period from July 1908 to November 1919. The minute books are held at The National Archives as WO 250/433 through WO 250/437. See the Research tab for more details.
What is this index?
Scarlets and Blues is one of three projects trying out a new indexing tool in Zooniverse. The others are HMS NHS: The Nautical Health Service and The RBGE Herbarium: Exploring Gesneriaceae, the African violet family (coming soon).
Zooniverse projects usually present records in a random order. These projects let you choose the records that you are interested in transcribing.
How do I choose a record?
You don't have to think about it if you don't want to -- you can just pick any record from the list.
If you do want to make a more conscious choice then you can look in the indexes of the minute books for something interesting to read. See How do I see the Minute Book indexes?, below, for how to find those indexes.
You pick a record in 3 stages. First you pick a workflow from Meetings or People.
Then you pick a "subject set". For Meetings the subject sets have been arranged by quarter within the year, like this:
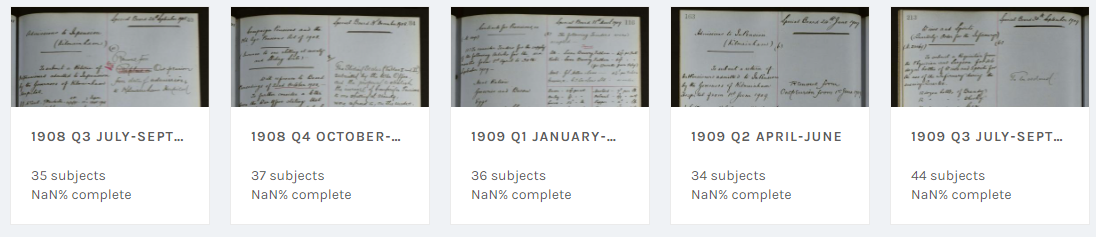
Finally, you pick a page within the subject set from the index. The Meetings index looks like this:
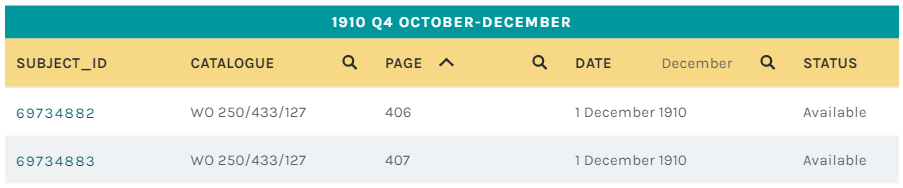
SUBJECT_ID links to the page. Click on this to start transcribing.
CATALOGUE is the planned catalogue reference for the record. The first two levels already exist in the catalogue and identify the minute book. The third level identifies the meeting and will be added to the catalogue using data from this project.
PAGE is the page number in the minute book -- helpful if you're using the index to find interesting subjects.
DATE is the date of the meeting -- helpful if you're following a reference in another meeting, or if you're interested in events at a particular time.
STATUS tells you the status of the record. Available means that the records still needs transcriptions. Already Seen means that you have already transcribed this record, but it is waiting to collect more transcriptions from others. Retired means that it has already collected enough transcriptions, but you can still look at if you want to refer to it for any reason.
You can search and sort on the columns in the index. In the example above, there is a search for dates in December and a sort on Page.
The People workflow has one subject set per book, named for the catalogue reference, like this:


You then choose a page from this index:


SUBJECT_ID and STATUS mean the same as in the Meetings index.
SURNAMES STARTING WITH tells you which letter surnames you will find here -- helpful if you're looking for a particular name.
How do I see the Minute Book indexes?
You might want to look at the indexes to find pages that you are interesting in working on. You can view them at the following locations:
- WO 250/433 (first minute book, July 1908 - March 1911)
- WO 250/434 (second minute book, March 1911 - September 1913)
- WO 250/435 (third minute book, October 1913 - October 1915)
- WO 250/436 (fourth minute book, October 1915 - December 1917)
- WO 250/437 (fifth minute book, January 1918 - November 1919)
At the top of your screen will be Preview an image of this record. Press this to open up a viewer. You can use the large arrows at the top to page through the index.




Look at this Talk page to see which subject set contains a particular page number.
Why are some pages missing?
Some of the pages are blank. We have left these pages out of the project, so you will see gaps in the numbering in the index.
If you come across evidence of other missing pages (for example, the middle of a meeting being missing) then please tell us on the Talk pages. At time of writing we know that we are missing pages 131, 132, 436 and 437 of WO 250/435.
Where can I find guidance on transcribing the records?
There is more information about transcription in the Field Guide, which you can see as you are transcribing records. You can also ask questions and see answers at the Transcription Queries Talk board. There are also video examples of how to transcribe pages.
Why do I have to press enter at the end of each line?
This will allow us to reconcile different transcriptions in smaller units, making this task easier and more likely to produce useful results.