
Results
Update – 18th March 2025
Now that our Zooniverse project has been running for just over five months, we thought we would update these initial comments to show you how far we have come in less than half a year thanks to your extraordinary work checking and transcribing historical wills.
Between the launch on the 15th October last year and early on the 18th March, you have checked a very impressive 358,551 lines of text and transcribed a further 40,944 lines from scratch. As each image has to be checked three times, or transcribed five times, this means that 112,142 lines of checked text have been completed, and 7,717 lines have been fully transcribed from scratch. This represents a fantastic contribution to our project – well done on deciphering so many fuzzy images, coping with odd spellings, and interpreting difficult handwriting.
This contribution has allowed us to correct a substantial amount of text produced by the handwritten text recognition (HTR) model as we can see from Figure 1. To create this figure, we have taken every line from the HTR model, compared it to each of your checks of that line and then counted the number of different words. The figure shows the number of cases where a given number of words were different. We can see that in nearly 75,000 cases there were no changes made to the HTR output, but in the vast majority of cases you have supplied us with at least one corrected word. In 28 per cent of checked transcriptions you changed one word, 30 per cent of the time you changed two and in 16 per cent of cases you changed 3. There are rather fewer cases where more than three words were changed; in only five per cent of checks did you supply four or more corrected words (the numbers for 6-10 changes are too small to appear on this graph). This is reassuring as it implies that the HTR model is not doing a completely awful job, but that you are also supplying meaningful changes that we can use to improve the model substantially.
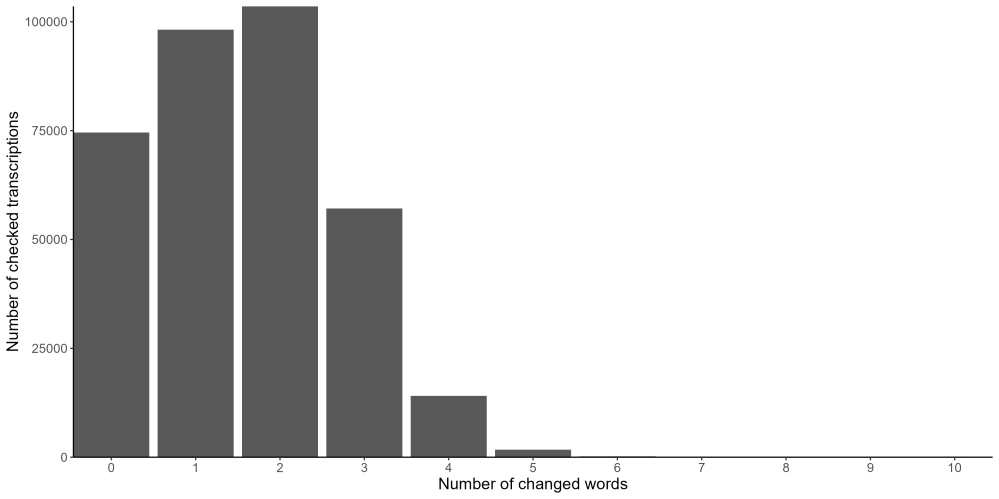
Figure 1, Number of lines checked by the number of corrected words.
It is important to remember that every corrected word that you supply makes an important contribution to the overall project. We can see this by considering the following example of a set of lines from the will of William Badland from Kington in Herefordshire, who died in 1786. Figure 2 shows a short extract from the start of his will.

Figure 2, Extract from the will of Williamn Badland, 1786.
The HTR output for the first four lines of his will was as follows:
wl wiill waepetatls wol god wmeell
snbm haallad of kington in the county of ereford
alinghty sood i give and beque aith to myloving
waife an the ffrlmtins in the roos ooed the suitther
Each of these lines have now been transcribed three times, and we have used words from each of those checked transcriptions to correct the decidedly inaccurate HTR transcription as follows, with each changed word indicated by italics.
in the name of god amen
Wm Badland of kington in the county of Hereford
almighty God I give and bequeath to my loving
wife all the ffurniture in the room and the kitchen
This was a particularly poor HTR transcription, and it serves to highlight some of the common difficulties the model faces. For example, it struggles with the large, ornate lettering at the start of the will, and it has problems with the noise on this image, particularly in the final line. However, there remains a degree of uncertainty as to why the model performs well in some areas and poorly in others. This makes your input all the more important, with every correction helping us improve the final version. So even if there is a word or letter you are unsure about, know that any corrections you can make will be of use!
In our previous update we had only applied the HTR models to eighteenth-century wills. Since then, we have move onto seventeenth- and sixteenth-century wills, and particular thanks to everyone who has helped with these earlier, trickier to read wills. Figure 3 shows a similar picture to Figure 1, but broken down by the century the will was made and proved. This shows the percentage of checked lines from each century. So no changes were needed for 16 per cent of sixteenth-century wills, a remarkable 33 per cent of seventeenth-century ones, and 19 per cent of eighteenth-century wills. Indeed, judging by the number of words requiring correction in each period, the HTR model used for the seventeenth-century has done well and outperformed the other two models. The sixteenth- and eighteenth-century models performed similarly, although the sixteenth-century model is substantially wrong more often than the models for the later periods; more than ten per cent of the time it required four or more words correcting, compared to four or five per cent of lines in the later periods. Given the difficult nature of the secretary hand seen in the earlier period, and the substantial increase in the variability of spelling and the use of abbreviations it is unsurprising that sometimes the model gets it very wrong.
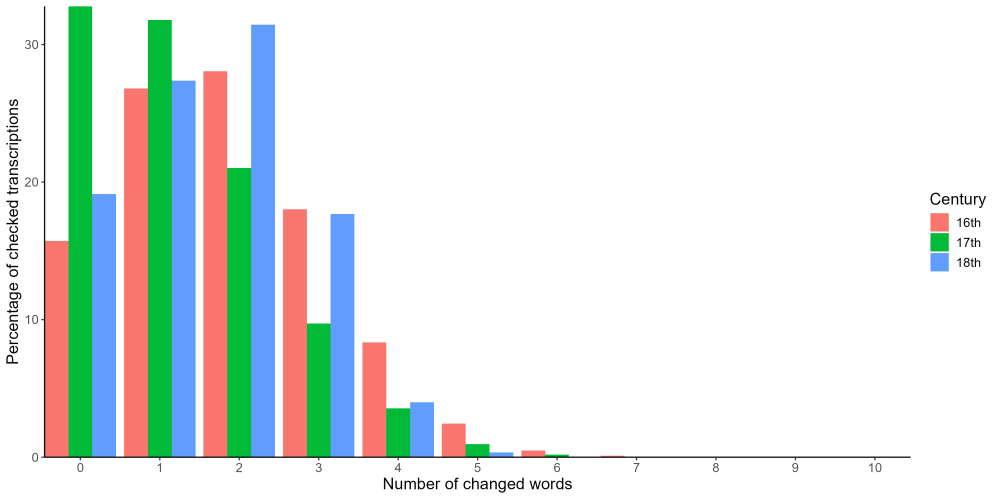
Figure 2, Percentage of lines checked requiring corrections by number of words change and century.
What is encouraging, however, are the large number of instances in which the model outputs require only little changes, something that has allowed us to begin to work on analysing the text of the wills, to start identify bequests, beneficiaries and so on. We will update this section when this analysis is a little more advanced to allow you to see the initial results of our enquiries. Until that time, our project blog has covered a range of different topics, and the Talk Boardscontain a great deal of detailed discussion of specific wills and topics.